What You Will Learn
You have a list of names in A2:A9 and some of them appear more than once. Alice shows up twice, Bob shows up twice, Dina shows up twice. You need to mark the first appearance of each name as "Keep" and every later repeat as "Duplicate".
This is the safer way to handle duplicates — instead of deleting rows immediately (which makes it hard to trace what was removed), you add a status label beside each row. Later you can review, filter, or delete based on that label. The audit cells at the bottom tell you the totals.
By the end of this challenge, you will know how to:
- Use
COUNTIF with an expanding range to detect duplicates.
- Use
IF to turn the count into a Keep/Duplicate label.
- Use
COUNTA and COUNTIF to summarize the results.
Your Sheet
Here is how the workbook is laid out:
| Area |
Content |
Your Job |
A2:A9 |
Raw name list (some names repeat) |
Leave as-is. This is your source data. |
B2:B9 |
Status column |
Write a formula that labels each row as Keep or Duplicate. |
B11 |
Total names |
Write a COUNTA formula. |
B12 |
Unique (Keep) names |
Write a COUNTIF formula. |
B13 |
Duplicate rows |
Write a COUNTIF formula. |
The image below shows the raw names, the status labels, and the summary section at the bottom.
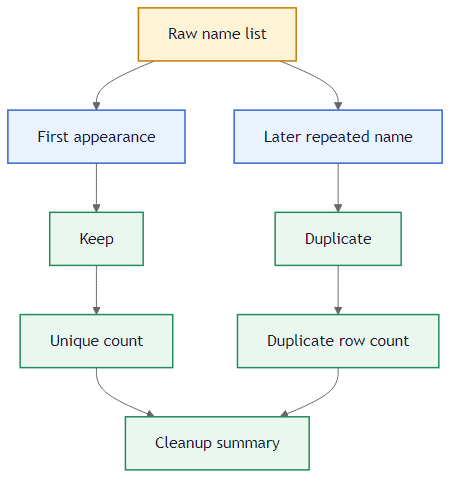 Raw names in column A, Keep/Duplicate labels in column B, summary below.
Raw names in column A, Keep/Duplicate labels in column B, summary below.
The Core Formula
The trick is an expanding range. The range $A$2:A2 starts at the first name and ends at the current row. When you fill the formula down, the end moves with it: $A$2:A3, $A$2:A4, and so on. At each row, COUNTIF looks back at everything above to see if the current name has appeared before.
Here is the formula for cell B2 (then fill it down to B9):
=IF(COUNTIF($A$2:A2,A2)=1,"Keep","Duplicate")
Breaking it down:
- COUNTIF($A$2:A2, A2) counts how many times the name in A2 appears from the start of the list down to the current row. The first time a name appears, this returns 1.
- =1 checks if this is the first appearance.
- IF(... ,"Keep", "Duplicate") shows "Keep" for the first appearance and "Duplicate" for every repeat.
The dollar sign on $A$2 locks the start of the range. The second part A2 is relative, so it moves down as you fill. This mixed reference — absolute start, relative end — is what makes the expanding range work.
The Summary Formulas
Once every row has a status label:
- B11:
=COUNTA(A2:A9) — counts how many names are in the list.
- B12:
=COUNTIF(B2:B9,"Keep") — counts the unique names.
- B13:
=COUNTIF(B2:B9,"Duplicate") — counts the duplicate rows.
COUNTA was used for total names because it counts non-empty cells. If a cell contains text like a name, COUNTA sees it. COUNT would not work here because names are text, not numbers.
Other Ways to Solve This
Method 2: MATCH with ROW
Instead of counting occurrences, you can compare the current row number against the row where that name first appears. If they match, it is the first occurrence.
=IF(ROW(A2)=MATCH(A2,$A$2:$A$9,0)+ROW($A$2)-1,"Keep","Duplicate")
This is a valid alternative but harder to read than the COUNTIF version. It also uses a fixed range ($A$2:$A$9) instead of an expanding one, which means it does not adapt if the list length changes.
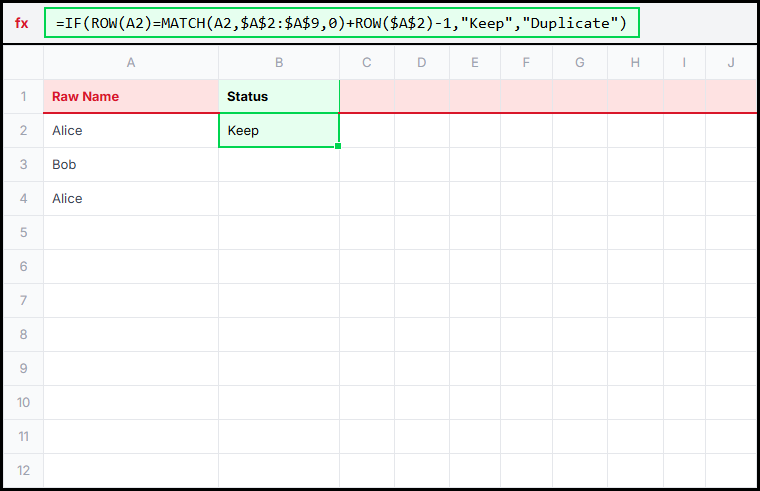 Method 2: Compare each row to the first time that name appears in the list.
Method 2: Compare each row to the first time that name appears in the list.
Method 3: Excel's Remove Duplicates Tool
The built-in tool (Data > Remove Duplicates) deletes repeated rows instantly. It is fast for one-time cleanup, but it removes data instead of marking it. If you need to review what was removed or explain the process to someone else, the COUNTIF approach is better.
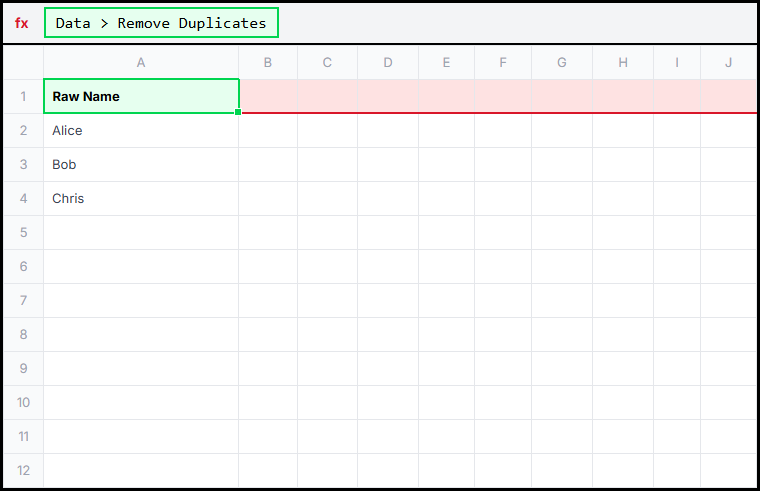 Method 3: Excel's built-in tool — fast but not auditable.
Method 3: Excel's built-in tool — fast but not auditable.
Functions Used in This Challenge
COUNTIF
Counts cells that match a condition. The expanding range pattern ($A$2:A2) lets COUNTIF look at the history as it moves down the list — useful whenever you need to detect the first occurrence of something.
IF
Returns one value when a condition is true and another when it is false. Here it turns the numeric COUNTIF result into a readable Keep/Duplicate label.
COUNTA
Counts non-empty cells. Unlike COUNT, it works on text values — which is why it is the right choice for counting names.
If your real data has extra spaces, COUNTIF(" Alice") and COUNTIF("Alice") will not match each other. Clean the names with TRIM first, or the duplicate check will miss repeats that only differ by spacing.
Write a formula in B2:B9 that labels each name as "Keep" (first appearance) or "Duplicate" (repeat). Then use COUNTA in B11 for the total, COUNTIF in B12 for unique names, and COUNTIF in B13 for duplicate rows.